
GLM-5 模型是智谱 AI 迄今最具野心的发布,总参数扩展到 7440 亿,采用 Mixture-of-Experts 架构,每个 token 激活 400 亿参数。GLM-5 模型于 2026 年 2 月 12 日发布,面向复杂系统工程和长周期 Agent 任务。本文将深入覆盖 GLM-5 模型的关键规格、架构设计和工程团队的实用指引。
GLM-5 模型规格
GLM-5 模型采用稀疏 MoE 架构,包含 256 个专家子网络,每个 token 路由到其中 8 个。5.9% 的激活率让 GLM-5 模型在保持 744B 参数知识容量的同时,推理成本接近一个仅有 40B 激活参数的小型稠密模型。
GLM-5 模型核心规格:
- 总参数: 744B
- 每 Token 激活参数: 40B
- 专家数量: 256 个专家,每次激活 8 个
- 上下文窗口: 200,000 tokens
- 最大输出: 128,000 tokens
- 预训练数据: 28.5 万亿 tokens
- 许可证: MIT 开源
与前代 GLM-4.5 相比,GLM-5 模型总参数从 355B 翻倍到 744B,激活参数从 32B 提升到 40B,预训练数据从 23T 扩展到 28.5T tokens。这些规模提升带来了编码、推理和 Agent 基准上的可衡量进步。
GLM-5 模型架构
GLM-5 模型架构的核心是支持混合推理模式切换的统一底座。不同于一些维护独立模型以适配不同推理深度的方案,GLM-5 模型使用单一基础,通过后训练策略区分 think 和 non-think 行为模式。
统一的 GLM-5 模型设计为部署提供了实际优势。团队无需管理不同任务类型的独立模型端点或路由逻辑。GLM-5 模型通过混合推理开关根据任务复杂度调整推理深度,在多种工作负载间灵活部署。
GLM-5 中的 DeepSeek 稀疏注意力
GLM-5 模型的关键架构创新是集成了 DeepSeek Sparse Attention。该注意力机制通过选择性地关注上下文窗口中最相关的部分来降低处理长输入序列的计算成本。对于 GLM-5 模型的 200K token 上下文,这尤为重要,因为标准稠密注意力在这个规模上的推理成本将高得不切实际。
DSA 在 GLM-5 模型中的实际效果是,团队可以使用完整的 200K 上下文窗口进行长文档分析和跨文件代码审查,而不会产生稠密注意力所需的相应成本增长。这使得 GLM-5 模型的长上下文能力可以真正用于生产,而非仅停留在理论最大值。
Slime:GLM-5 的异步 RL 基建
GLM-5 模型的后训练利用了 slime,一个由 THUDM 团队开发的异步强化学习基础设施。传统同步 RL 训练会在生成和训练步骤之间产生瓶颈。slime 框架为 GLM-5 模型解耦了这些阶段,在关键的后训练阶段实现了更高的吞吐量和更快的迭代周期。
这一基建选择让 GLM-5 模型团队能更快速地迭代对齐和能力改进,对 GLM-5 模型在 Agent 和推理基准上的出色表现做出了贡献。
GLM-5 模型变体
当前官方文档与定价页明确列出的 GLM-5 文本模型主要是两个条目:
GLM-5 是旗舰变体,完整的 744B/40B 激活参数配置,200K 上下文窗口和 128K 最大输出。这个 GLM-5 模型变体在任务类别中提供最高质量,推荐用于复杂工程任务、长文档分析和生产 Agent 工作流。
GLM-5-Code 是面向软件工程场景的专用变体,按 token 定价高于标准 GLM-5。
在部分工具或社区内容中你可能会看到 Air、Flash 等名称。把它们视为账号或渠道相关标签更稳妥,生产使用前请先在你的控制台确认可用性和配额限制。
GLM-5 模型能力
GLM-5 模型支持多项适合生产工程工作流的能力:
Function Calling 使 GLM-5 模型能在推理过程中调用外部工具和 API。GLM-5 模型支持并行函数调用,在单步中进行多个工具调用,提高 Agent 工作流效率。
混合推理 让 GLM-5 模型根据任务需求在浅层和深层推理模式间切换。简单查询可以在 non-think 模式下快速处理,复杂多步问题则受益于 GLM-5 模型更深层的 think 模式。
OpenAI 兼容 API 意味着 GLM-5 模型可以使用现有的 OpenAI SDK 集成。团队只需更改 base URL 和 API key 即可切换到 GLM-5 模型。
GLM-5 模型 vs 前沿竞品
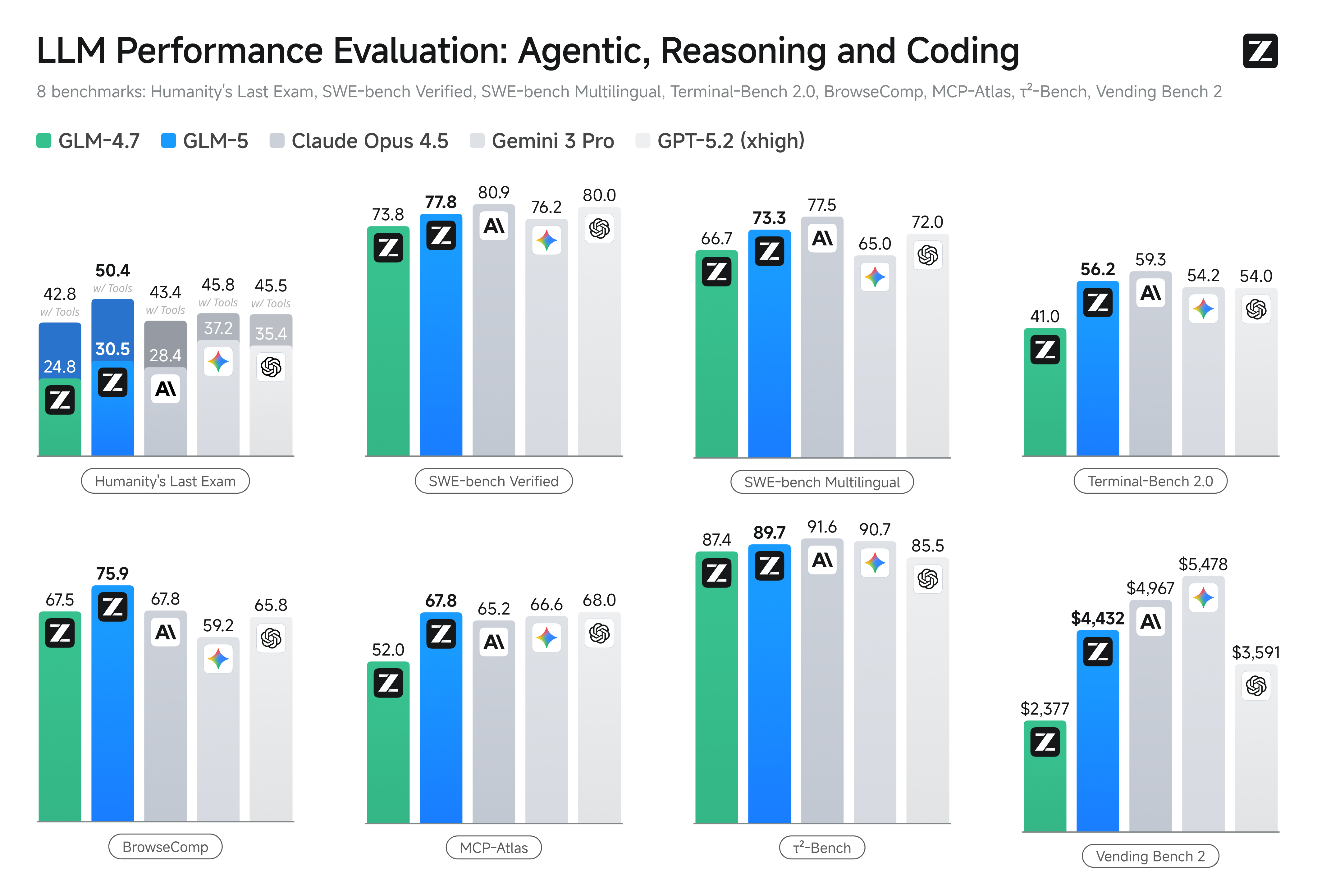
GLM-5 模型在关键基准上与 GPT-5.2、Claude Opus 4.5 和 Gemini 3.0 Pro 直接竞争。在 SWE-bench Verified 上,GLM-5 模型得分 77.8,介于 Gemini 3.0 Pro 的 76.2 和 Claude Opus 4.5 的 80.9 之间。在 Agent 任务上,GLM-5 模型在 Vending Bench 2 和 BrowseComp 上领先所有开源模型。
GLM-5 模型的核心竞争优势在于接近前沿的性能与显著更低的定价和开源权重的组合。需要前沿级能力但希望避免私有供应商锁定的团队应该将 GLM-5 模型作为可行替代方案进行评估。
评估建议
评估 GLM-5 模型的团队应使用旗舰 GLM-5 对具体工作负载运行受控基准测试,并在编码质量是核心指标时与 GLM-5-Code 做对照。关注编码修复质量、工具编排可靠性和长周期任务完成率,而非仅看聚合基准分数。GLM-5 模型的真正价值取决于它在你特定用例上的表现。