
Stage#1
统一模型底座
GLM-5 使用单一统一底座,无需在思考与非思考场景间切换不同模型。
GLM-5 模型中心
评估 GLM-5 能力上限,对比 benchmark 分数,查看 API 价格,探索 架构细节 — 一站式完成。
744B
40B
200K
MIT
社区声音
来自 AI 社区的深度评测和教程视频,展示 GLM-5 的核心能力。
完整实测覆盖编码质量、多步任务执行,以及在 Agent 编码基准中的多模型对比。
AICodeKing
44.2K views · 2026-02-11
以浏览器自动化、游戏生成和 Python 3D 任务做实操演示,评估真实代码生成质量。
Bijan Bowen
15K views · 2026-02-11
从快速编码提示到 Agent 工程管线的用例演示,探索 GLM-5 真实部署路径。
Fahd Mirza
3.5K views · 2026-02-11
GLM-5 是智谱 AI 第五代大语言模型,面向复杂系统工程与长周期 Agent 任务。从 GLM-4.5 的 355B/32B 激活参数升级到 744B/40B 激活,预训练数据从 23T 提升到 28.5T tokens。
Think / Non-think 共享同一模型底座,通过后训练策略区分推理风格。
DeepSeek Sparse Attention 降低推理成本,同时保留 200K 上下文处理能力。
GLM-5 权重已在 Hugging Face / ModelScope 发布,采用 MIT 许可证,同时支持多平台 API 接入。
GLM-5 采用统一模型架构,支持混合推理模式切换。Think / Non-think 共享同一底座,配合 DSA 长上下文优化与 slime 异步 RL 训练基建。
744B
总参数
40B
激活参数
28.5T Tokens
预训练数据
统一 Think/Non-think
推理模式
GLM-5 使用单一统一底座,无需在思考与非思考场景间切换不同模型。
Think 与 Non-think 的差异来自后训练阶段,便于在质量与延迟之间灵活配置。
支持按任务复杂度灵活启用混合推理模式,适配不同部署场景。
DeepSeek Sparse Attention 在长上下文任务中降低推理成本,提升大输入序列处理效率。
slime 框架提供异步强化学习能力,提高训练吞吐量并加快迭代周期。
GLM-5 支持 Function Calling 和并行工具调用,适配复杂多步 Agent 工作流。
GLM-5 在不同主流平台的上下文窗口与输出上限,不同平台展示的实际限制可能存在差异。
200K context / 最高 128K output
GLM-5(docs.z.ai)
202,752 context
GLM-5(OpenRouter)
最高 202,752
OpenRouter 最大完成
不同端点限制可能不同
平台差异说明
200K 上下文窗口可支撑长文档问答、跨文件代码分析和多轮计划执行。
官方文档中 GLM-5 支持最高 128K 输出 tokens;不同平台与端点的实际输出上限可能不同。
202,752 context 来自 OpenRouter 模型页,生产接入请核对目标平台实测限制。
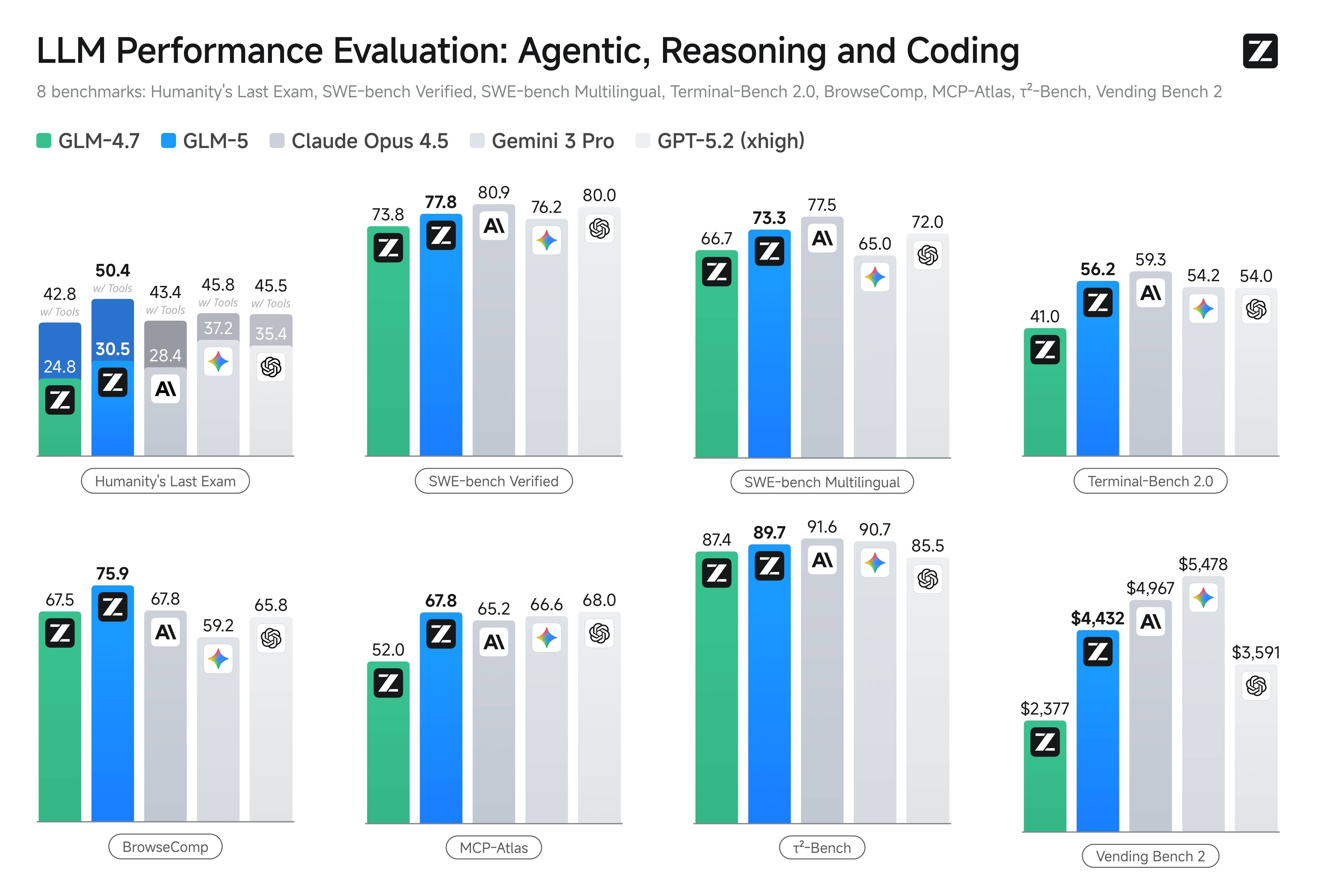
公开 benchmark 图表覆盖 Agentic、Reasoning、Coding 与 Long-horizon 任务,便于横向模型比较。
数据来源:docs.z.ai 与 z.ai/blog/glm-5,抓取日期 2026-02-12
8 项公开 benchmark:Humanity's Last Exam、SWE-bench、Terminal-Bench、MCP-Atlas、Vending Bench 2 等。
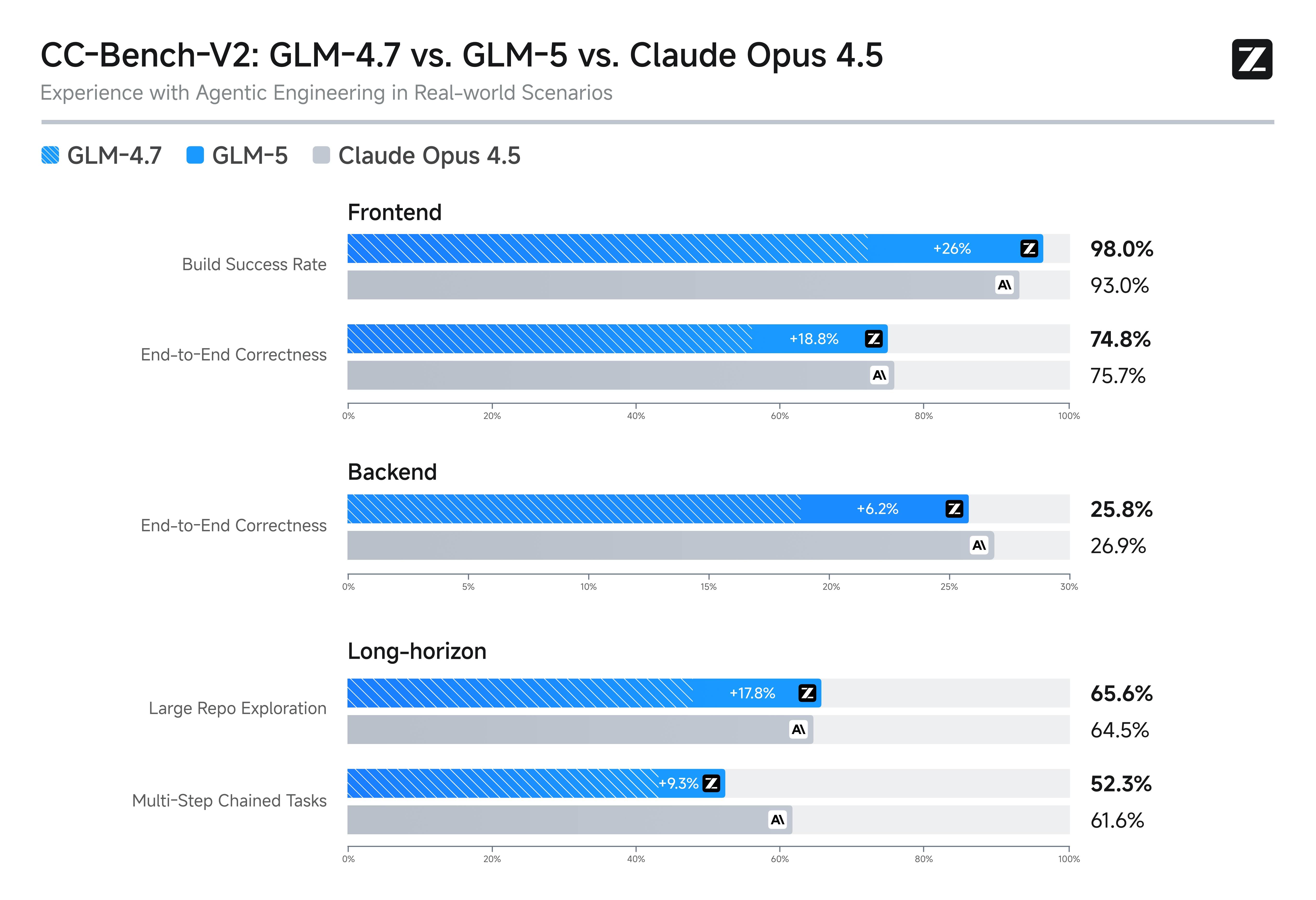
真实工程场景下的 Frontend、Backend 与 Long-horizon 对比图。
77.8
SWE-bench Verified
GLM-5 在 SWE-bench Verified 上的得分,衡量真实代码修复能力。
73.3
SWE-bench Multilingual
多语言软件工程任务中的表现分数。
56.2
Terminal-Bench 2.0
终端代理任务基准分数,衡量命令行任务完成能力。
$4,432
Vending Bench 2
GLM-5 在商业模拟 benchmark 中达到的最终余额。
价格来自 docs.z.ai 与 OpenRouter,数据截至 2026-02-12。此处统一按 USD 展示,上线前请再次核对各平台最新报价。
$1.00 / 1M tokens
GLM-5 输入
$0.20 / 1M tokens
GLM-5 缓存输入
$3.20 / 1M tokens
GLM-5 输出
$1.20 输入 / $5.00 输出
GLM-5-Code
输入 $1.00 / 1M、缓存输入 $0.20 / 1M、输出 $3.20 / 1M,美元计价。
输入 $1.20 / 1M、缓存输入 $0.30 / 1M、输出 $5.00 / 1M,美元计价。
官方价格页标注 Cached Input Storage 为限时免费。
OpenRouter 页面显示 $1 / 1M 输入、$3.20 / 1M 输出,美元计价。
docs.z.ai 与 OpenRouter 均以每 1M tokens 为单位展示价格,接入前请核对平台计费粒度。
跨平台最终账单可能受路由策略、平台加价与缓存行为影响。
GLM-5 在系统工程负载、长周期 Agent 任务、竞争力价格与超低幻觉率方面表现突出。
GLM-5 面向复杂系统工程与高复杂度执行工作流,支持多步工具调用。
关于 GLM-5 benchmark、API 价格、上下文窗口与模型能力的常见问题。
截至 2026-02-12,docs.z.ai 上 GLM-5 为输入 $1.00/1M、缓存输入 $0.20/1M、输出 $3.20/1M;GLM-5-Code 为输入 $1.20/1M、缓存输入 $0.30/1M、输出 $5.00/1M。OpenRouter 上 GLM-5 为 $1/1M 输入、$3.20/1M 输出。
官方文档显示 GLM-5 支持 200K 上下文窗口、最高 128K 输出。OpenRouter 当前展示 202,752 context;不同平台端点的实际限制可能不同。
是的。GLM-5 总参数 744B,每个 token 激活 40B,采用 256 个专家、每次激活 8 个的稀疏 MoE 架构。
GLM-5 在 SWE-bench Verified 上得分 77.8。公开对比图中,Claude Opus 4.5 为 80.9,Gemini 3.0 Pro 为 76.2。GLM-5 在 Vending Bench 2 中排名开源权重模型第一。
OpenRouter 是路由平台,可能存在平台级路由与加价策略。上线前请分别核对各平台的最终计费规则与单位。
是的。GLM-5 权重已在 Hugging Face 和 ModelScope 发布,MIT 许可证,支持 vLLM、SGLang 本地部署。