
GLM-5 benchmark 结果清晰地展示了这个模型在哪些领域领先、在哪些领域仍有差距。本文不依赖单一的聚合分数,而是逐个拆解 GLM-5 benchmark 的各个大类,帮助团队做出有据可依的评估决策。本文引用的所有 GLM-5 benchmark 数据来自 docs.z.ai 和 z.ai 发布博客上的公开图表。
GLM-5 Benchmark 总览
GLM-5 benchmark 套件覆盖八大评测类别,横跨编码、推理、Agent 任务和长周期工作流。智谱 AI 将 GLM-5 定位为在开源模型中达到 SOTA 水平,同时在大多数 GLM-5 benchmark 任务上缩小了与私有前沿模型的差距。
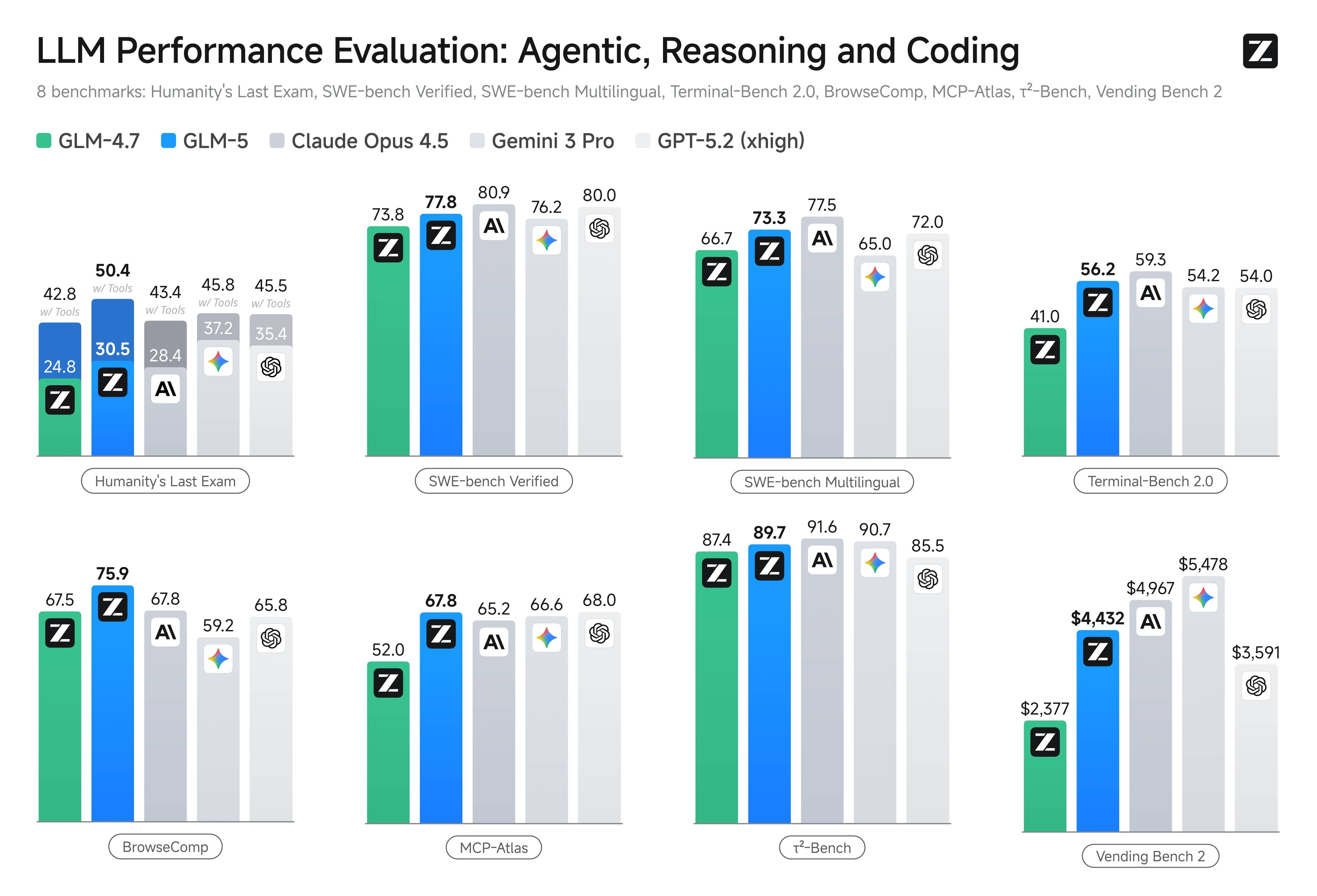
GLM-5 benchmark 结果显示,相比上一代 GLM-4.7,所有类别均有显著提升,其中 Agent 和长周期任务评测的增长幅度最大。
SWE-bench:GLM-5 编码 Benchmark
SWE-bench Verified 是工程团队最关注的 GLM-5 benchmark 指标之一。这项 GLM-5 benchmark 衡量的是通过生成正确代码补丁来解决真实 GitHub issue 的能力。GLM-5 在 SWE-bench Verified 上得分 77.8,高于 Gemini 3.0 Pro 的 76.2,低于 Claude Opus 4.5 的 80.9。
在多语言软件工程方面,GLM-5 在 SWE-bench Multilingual 上的 benchmark 得分为 73.3。这项 GLM-5 benchmark 表明 GLM-5 具备扎实的跨语言能力,对使用 Python、JavaScript、TypeScript、Java 等多语言代码库的团队尤为重要。
SWE-bench GLM-5 benchmark 之所以特别相关,是因为它测试的是真实代码修复任务而非合成编码练习。77.8 的 GLM-5 benchmark 分数意味着 GLM-5 可以可靠地修复生产代码库中的真实 bug,但团队仍应在自己特定的代码库和编码模式上验证。
Terminal-Bench:GLM-5 Agent Benchmark
Terminal-Bench 2.0 评估模型在命令行任务完成方面的能力,是构建基于终端的 Agent 工作流的团队的关键 GLM-5 benchmark。GLM-5 在此 benchmark 上得分 56.2,展示了理解命令行工具、组合多步终端操作和处理 shell 环境中错误恢复的能力。
这项 GLM-5 benchmark 对 DevOps 和基础设施自动化场景尤为重要,模型需要在复杂的命令行环境中导航、解析工具输出、并将操作链接在一起以实现系统管理目标。
Vending Bench 2:GLM-5 商业模拟 Benchmark
Vending Bench 2 是一项 Agent 类 GLM-5 benchmark,模拟经营一家企业,要求模型做出战略决策、管理资源,并在多轮交互中优化利润。GLM-5 达到 $4,432 的最终余额,在所有开源模型中排名第一。
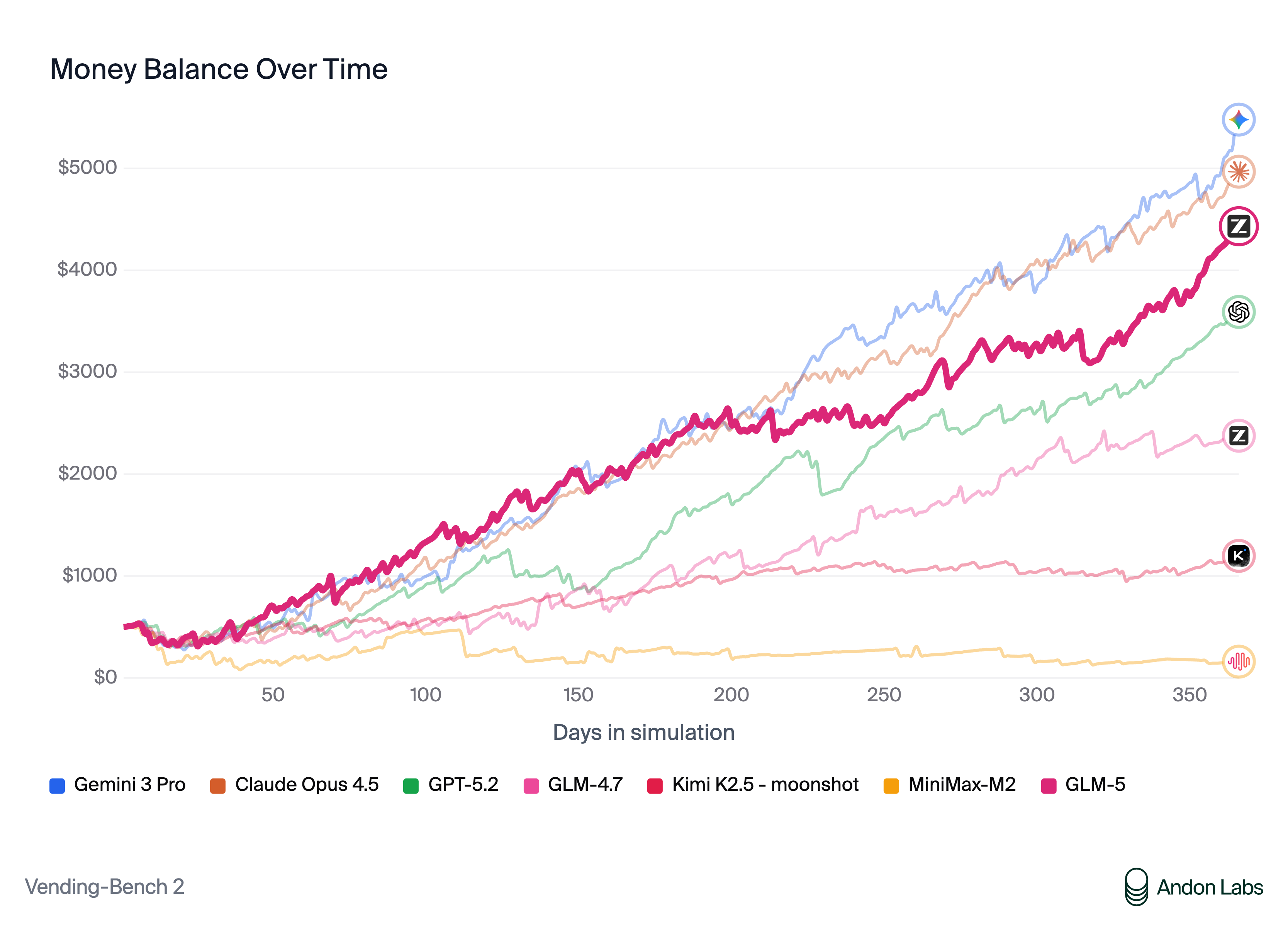
这项 GLM-5 benchmark 测试的是超越单轮代码生成的长周期规划和决策能力。Vending Bench 2 的强劲表现表明 GLM-5 非常适合需要在多步骤中持续推理的 Agent 工作流,如自动化项目管理、资源分配和战略规划任务。
MCP-Atlas:GLM-5 工具编排 Benchmark
MCP-Atlas 评估多步工具使用和编排能力,GLM-5 benchmark 得分 67.8。该 benchmark 测试模型将复杂任务分解为工具调用、处理工具结果、并将多个工具调用串联起来解决问题的能力。
对于构建依赖 Function Calling 和并行工具使用的 Agent 系统的团队,这项 GLM-5 benchmark 提供了最直接的生产就绪信号。67.8 的分数表明工具编排能力强但非完美,生产系统应包含工具调用可靠性的错误处理和重试逻辑。
BrowseComp:GLM-5 网页导航 Benchmark
BrowseComp 测试模型通过多步浏览任务导航网页内容并提取信息的能力。GLM-5 在开源模型中表现强劲,反映了其理解网页结构、跟踪链接和从多个来源综合信息的能力。
这项 GLM-5 benchmark 与构建网页抓取 Agent、研究助手和自动化数据收集工作流的团队相关。
CC-Bench-V2:GLM-5 工程 Benchmark
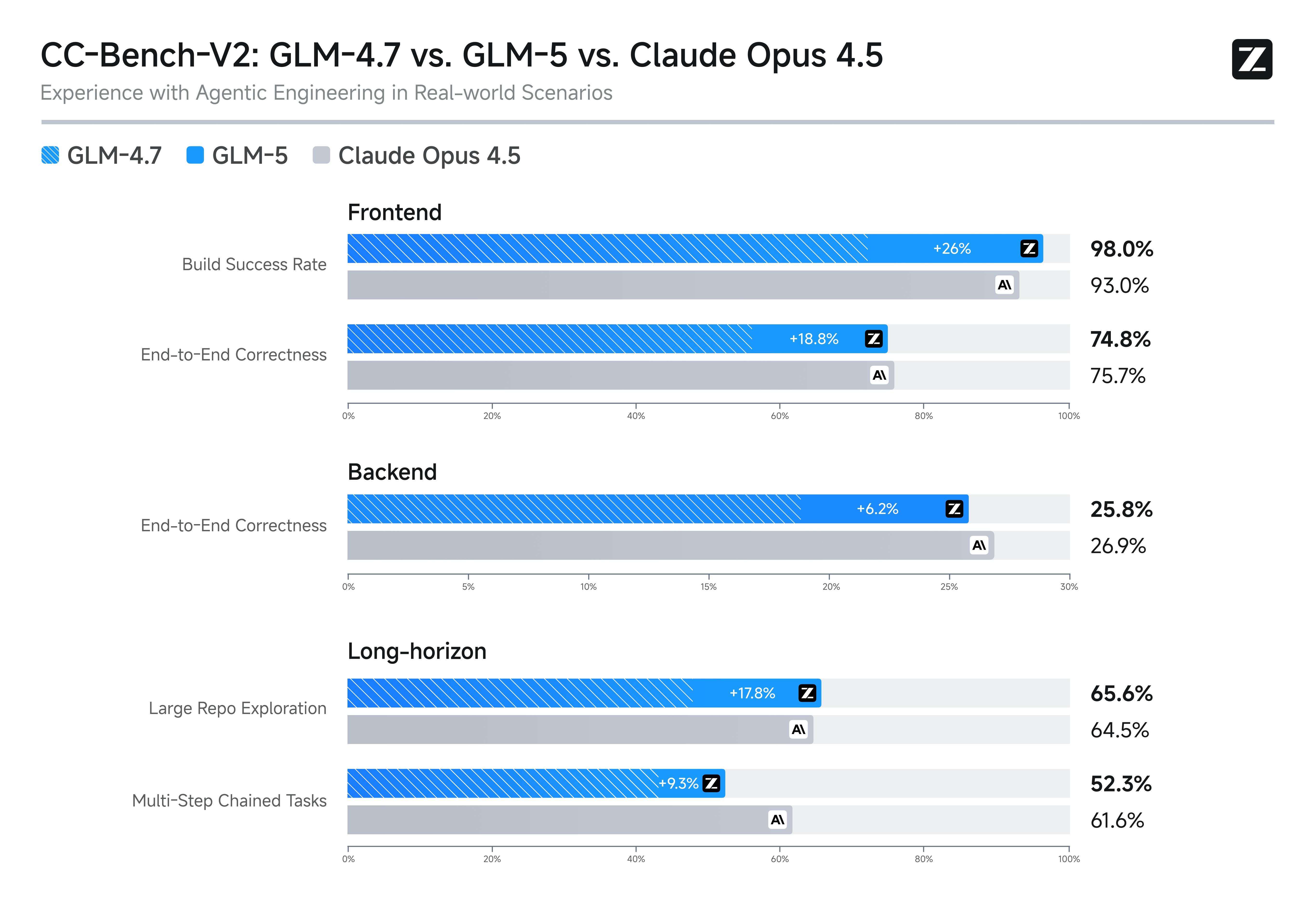
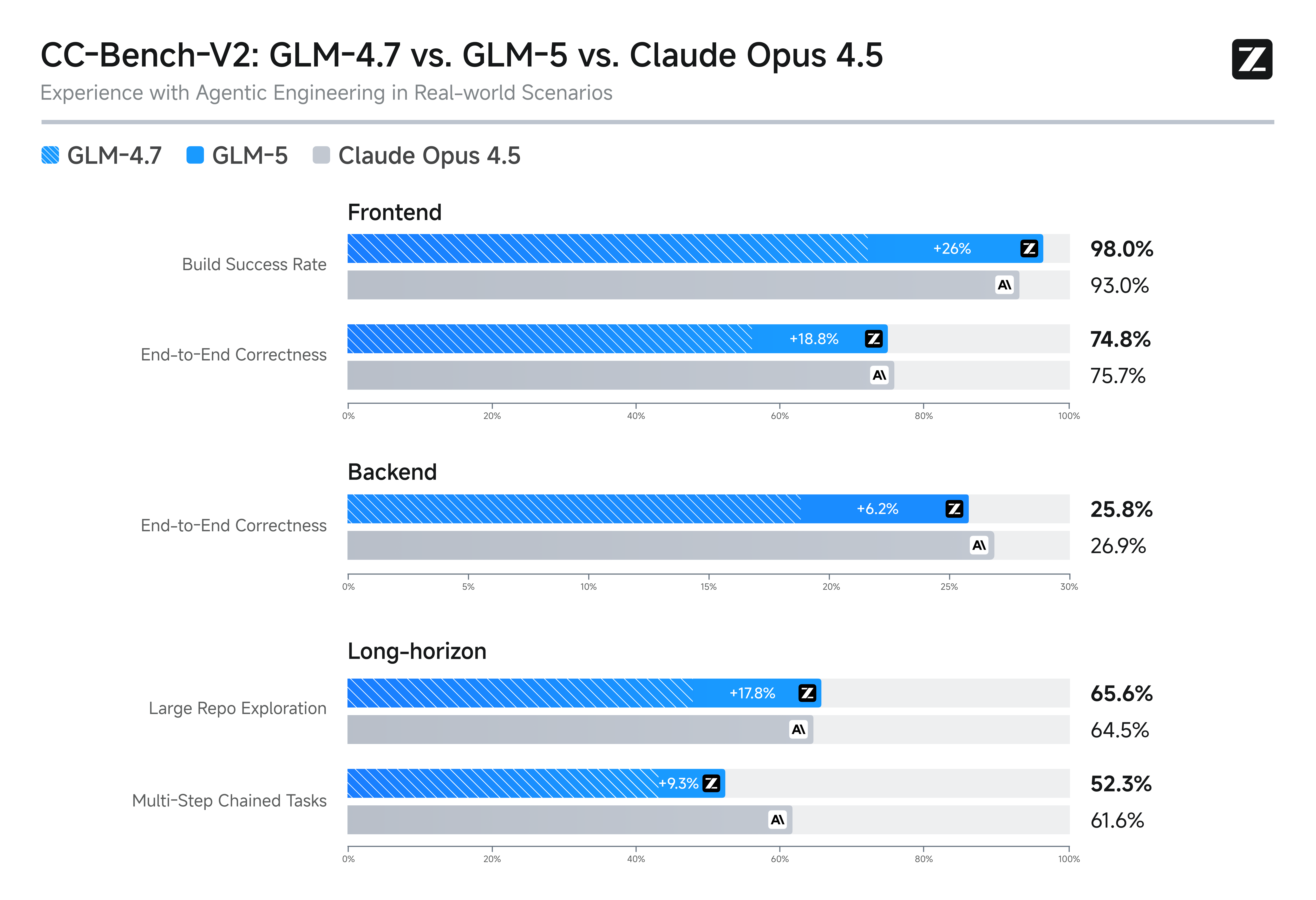
CC-Bench-V2 是一项综合性的 GLM-5 benchmark,覆盖前端、后端和长周期三大真实工程场景。该 benchmark 超越孤立的编码任务,评估模型在涉及多文件、多依赖和架构考量的现实工程项目中的工作能力。
CC-Bench-V2 的 GLM-5 benchmark 结果显示,三个类别均有竞争力的表现,后端工程任务中尤为突出,GLM-5 的系统工程定位在此提供了优势。
幻觉率:GLM-5 可靠性 Benchmark
最值得关注的 GLM-5 benchmark 结果之一是在 Artificial Analysis Intelligence Index v4.0 上创纪录的低幻觉率。GLM-5 在 AA-Omniscience Index 上得分 -1,比前代提高 35 分,在知识可靠性方面领先整个 AI 行业。
这项 GLM-5 benchmark 对事实准确性至关重要的生产场景意义重大。低幻觉率意味着团队可以对 GLM-5 在文档生成、研究综合和事实查询方面的输出给予更高信任,但高风险决策仍需人工核验。
从 GLM-5 Benchmark 到决策
虽然 GLM-5 benchmark 分数提供了有用的方向性信号,但生产团队不应仅依赖 benchmark。推荐的评估工作流是:
- 将评估拆分为编码修复、工具使用和长周期规划三个类别
- 每个类别构建 20 到 50 个真实样本的代表性测试集
- 对当前模型和至少一个替代方案进行并行测试
- 追踪成功率、重试率、延迟和每任务成本
- 按工作负载中任务类型的实际分布加权结果
这个流程比任何单一的 GLM-5 benchmark 分数都更具决策价值,能让你确信 GLM-5 是否适合你的特定生产需求。