
GLM-5 is the fifth-generation large language model developed by Zhipu AI, released on February 12, 2026. With 744 billion total parameters and 40 billion active parameters per token, GLM-5 represents a significant leap forward in open-source AI model capability. This guide breaks down what GLM-5 is, how it works, and why it matters for developers and engineering teams evaluating frontier models in 2026.
GLM-5 at a Glance
GLM-5 is a Mixture-of-Experts model with 256 experts and 8 activated per token, resulting in a 5.9% sparsity rate. The GLM-5 model scales up from its predecessor GLM-4.5, which had 355 billion total parameters and 32 billion active parameters. The pretraining dataset also grew substantially, from 23 trillion tokens to 28.5 trillion tokens, giving GLM-5 a broader knowledge base and improved reasoning capabilities.
The GLM-5 model supports a 200K token context window with up to 128K output tokens, making it suitable for long-document analysis, cross-file code review, and complex multi-step planning tasks. Official docs currently list GLM-5 as the flagship entry, and the pricing page also lists GLM-5-Code for coding-focused workloads.
GLM-5 Architecture Details
The GLM-5 architecture introduces several innovations that set it apart from previous generations. At its core, GLM-5 uses a unified model base that supports hybrid reasoning mode switching. This means the same GLM-5 model can operate in both "think" and "non-think" modes, with differences introduced during post-training rather than requiring separate model deployments.
One of the key architectural features of GLM-5 is the integration of DeepSeek Sparse Attention, which reduces inference cost while preserving long-context capability. This is particularly important for production deployments where GLM-5 needs to handle large input sequences without proportionally increasing compute costs.
The GLM-5 training process also benefits from a novel asynchronous reinforcement learning infrastructure called slime. Developed by the THUDM team, slime enables higher training throughput and faster iteration cycles, which was critical for training a model at the GLM-5 scale.
GLM-5 Benchmark Performance
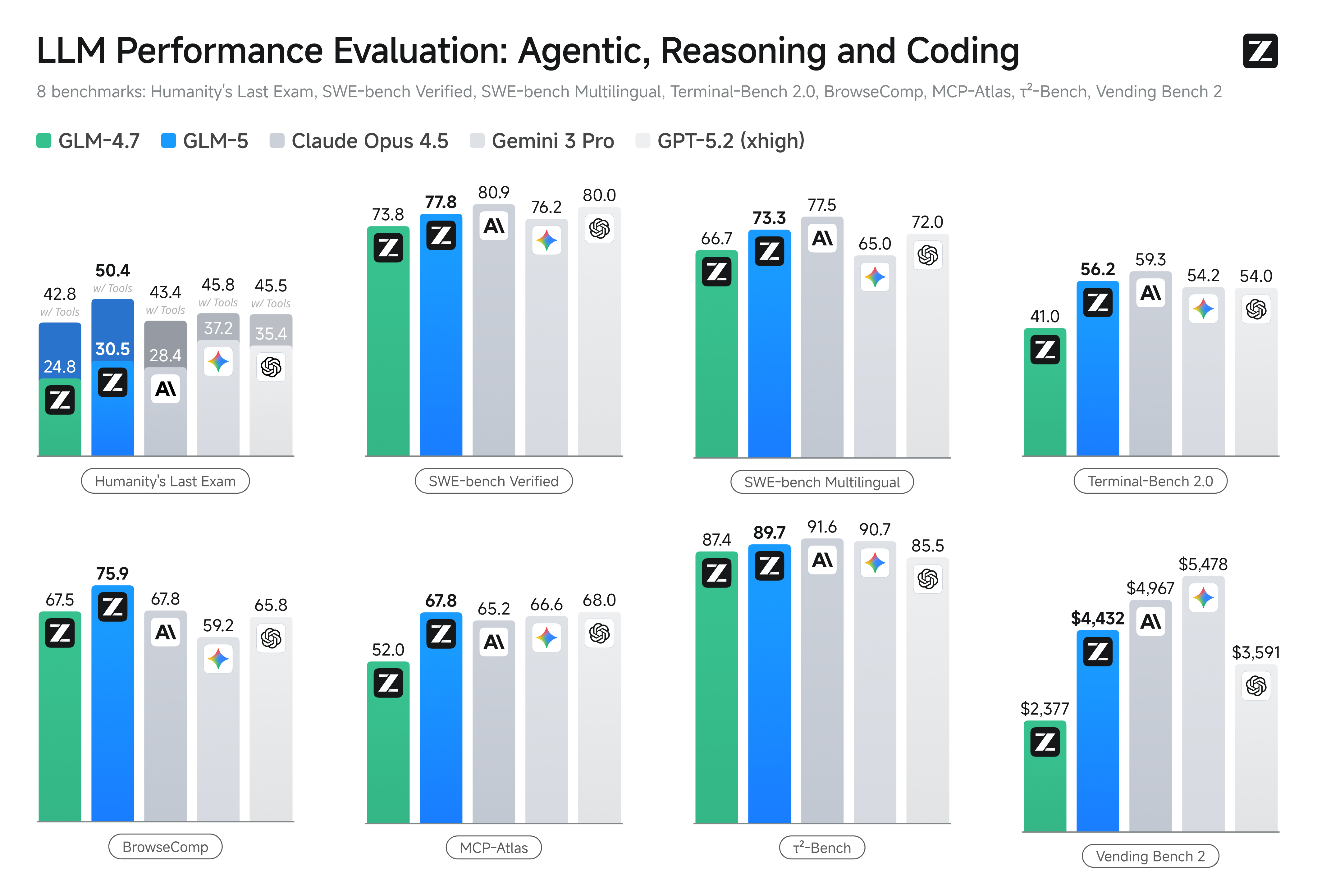
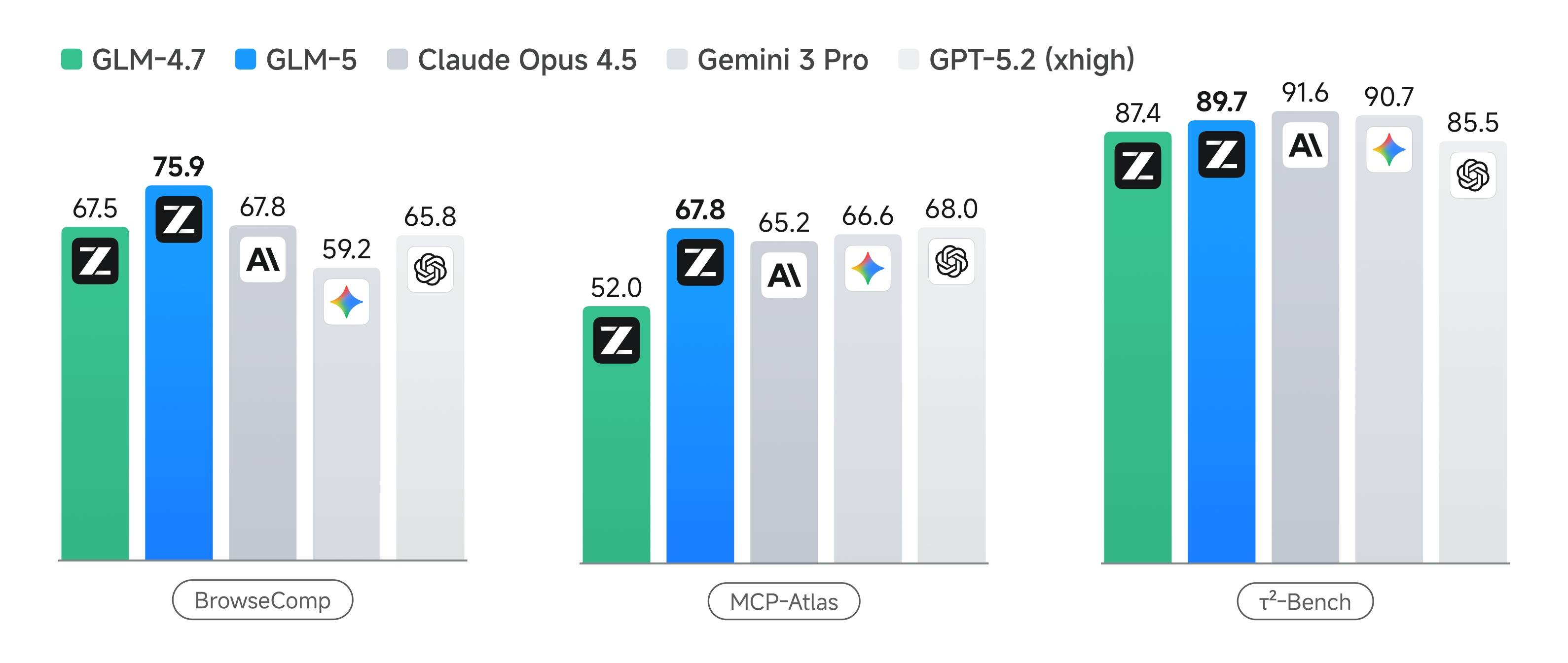
GLM-5 delivers competitive benchmark results across coding, reasoning, and agentic task categories. On SWE-bench Verified, GLM-5 scores 77.8, outperforming Gemini 3.0 Pro at 76.2 and approaching Claude Opus 4.5 at 80.9. For multilingual software engineering tasks, GLM-5 achieves 73.3 on SWE-bench Multilingual.
In agentic and long-horizon evaluations, GLM-5 ranks first among open-source models on Vending Bench 2 with a final balance of $4,432. The GLM-5 model also shows strong performance on Terminal-Bench 2.0 with a score of 56.2, and on MCP-Atlas with 67.8 for multi-step tool orchestration tasks.
Perhaps most notably, GLM-5 achieves a record-low hallucination rate on the Artificial Analysis Intelligence Index v4.0, with a score of -1 on the AA-Omniscience Index. This represents a 35-point improvement over its predecessor and positions GLM-5 as a leader in knowledge reliability.
GLM-5 API Access and Pricing
Teams can access GLM-5 through multiple providers. On the first-party api.z.ai pricing page (USD), GLM-5 is listed at $1.00 per million input tokens, $0.20 cached input tokens, and $3.20 per million output tokens. GLM-5-Code is listed at $1.20 input and $5.00 output per million tokens.
Through OpenRouter, z-ai/glm-5 is listed at $1.00 per million input tokens and $3.20 per million output tokens, with a 202,752-token context length in the model API.
The GLM-5 API is OpenAI-compatible, meaning teams can use existing OpenAI SDK integrations with minimal changes to their codebase. GLM-5 supports Function Calling and parallel tool calls, enabling complex agentic workflows with multi-step orchestration.
GLM-5 Open Source Availability
According to the official release post, GLM-5 weights are open-sourced under the MIT License on both Hugging Face and ModelScope. The release guidance highlights local deployment options such as vLLM and SGLang.
For organizations concerned about vendor lock-in or data sovereignty, the open-weight availability of GLM-5 provides a path to self-hosted frontier-level AI capability. Teams can fine-tune GLM-5 for specific use cases, deploy it on their own infrastructure, and maintain full control over their AI stack.
Who Should Evaluate GLM-5
GLM-5 is particularly relevant for teams working on complex systems engineering, long-horizon agentic tasks, and production coding workflows. The combination of strong benchmark performance, competitive pricing, and open-weight availability makes GLM-5 a compelling option for organizations that need frontier-level capability without the cost structure of proprietary alternatives.
Engineering teams evaluating GLM-5 should focus on three areas: coding repair and execution quality using SWE-bench style tasks, tool orchestration stability with Function Calling and parallel tool use, and long-horizon execution behavior in Terminal-Bench and MCP-style workflows. Running controlled pilots with real prompts and tool stacks will provide the most decision-grade signal for GLM-5 adoption.