
The GLM-5 model represents Zhipu AI's most ambitious release to date, scaling to 744 billion total parameters with a Mixture-of-Experts architecture that activates 40 billion parameters per token. Released on February 12, 2026, the GLM-5 model is designed for complex systems engineering and long-horizon agentic tasks. This technical deep dive covers the key specifications, architectural decisions, and practical implications of the GLM-5 model for engineering teams.
GLM-5 Model Specifications
The GLM-5 model uses a sparse MoE architecture with 256 expert sub-networks, routing each token through 8 selected experts. This 5.9% activation rate allows the GLM-5 model to maintain the knowledge capacity of a 744B parameter model while keeping inference costs comparable to a much smaller dense model with only 40B active parameters per forward pass.
The core GLM-5 model specifications are:
- Total Parameters: 744 billion
- Active Parameters per Token: 40 billion
- Expert Count: 256 experts, 8 activated per token
- Context Window: 200,000 tokens
- Maximum Output: 128,000 tokens
- Pretraining Data: 28.5 trillion tokens
- License: MIT open-source
Compared to its predecessor GLM-4.5, the GLM-5 model roughly doubles the total parameter count from 355B to 744B, increases active parameters from 32B to 40B, and expands pretraining data from 23T to 28.5T tokens. These scale-ups translate to measurable gains across coding, reasoning, and agentic benchmarks.
GLM-5 Model Architecture
The GLM-5 model architecture centers on a unified base that supports hybrid reasoning mode switching. Unlike some competing approaches that maintain separate models for different reasoning depths, the GLM-5 model uses a single foundation with "think" and "non-think" behavioral modes differentiated through post-training strategies.
This unified GLM-5 model design offers practical advantages for deployment. Teams do not need to manage separate model endpoints or routing logic for different task types. The GLM-5 model can adapt its reasoning depth based on task complexity through the hybrid reasoning switch, allowing flexible deployment across varied workload profiles.
DeepSeek Sparse Attention in GLM-5
A key architectural innovation in the GLM-5 model is the integration of DeepSeek Sparse Attention. This attention mechanism reduces the computational cost of processing long input sequences by selectively attending to the most relevant parts of the context window. For the GLM-5 model's 200K token context, this is particularly important because standard dense attention would make inference prohibitively expensive at this scale.
The practical impact of DSA in the GLM-5 model is that teams can use the full 200K context window for long-document analysis and cross-file code review without the proportional cost increase that dense attention would require. This makes the GLM-5 model's long-context capability practical for production use rather than a theoretical maximum.
Slime: Asynchronous RL for GLM-5
The GLM-5 model's post-training leverages slime, an asynchronous reinforcement learning infrastructure developed by the THUDM team. Traditional synchronous RL training creates bottlenecks where generation and training steps must wait for each other. The slime framework decouples these stages for the GLM-5 model, enabling higher throughput and faster iteration cycles during the critical post-training phase.
This infrastructure choice allowed the GLM-5 model team to iterate more rapidly on alignment and capability improvements, contributing to the GLM-5 model's strong performance on agentic and reasoning benchmarks.
GLM-5 Model Variants
Current official docs and pricing explicitly list two GLM-5 text model entries:
GLM-5 is the flagship variant with the full 744B/40B-active parameter configuration, 200K context window, and 128K max output. This GLM-5 model variant delivers the highest quality across task categories and is recommended for complex engineering tasks, long-document analysis, and production agentic workflows.
GLM-5-Code is a specialized variant optimized for software engineering workloads with a higher per-token price point.
Some tools or community posts may mention additional names such as Air or Flash. Treat those as account- or channel-specific labels and verify current availability in your own console before relying on them in production.
GLM-5 Model Capabilities
The GLM-5 model supports several capabilities that make it suitable for production engineering workflows:
Function Calling enables the GLM-5 model to invoke external tools and APIs as part of its reasoning process. The GLM-5 model supports parallel function calls, allowing multiple tool invocations in a single step for more efficient agentic workflows.
Hybrid Reasoning allows the GLM-5 model to switch between shallow and deep reasoning modes based on task requirements. Simple queries can be handled quickly in non-think mode, while complex multi-step problems benefit from the GLM-5 model's deeper think mode.
OpenAI-Compatible API means the GLM-5 model can be accessed using existing OpenAI SDK integrations. Teams can switch to the GLM-5 model by changing the base URL and API key in their existing code, with no other modifications required.
GLM-5 Model vs. Frontier Competitors
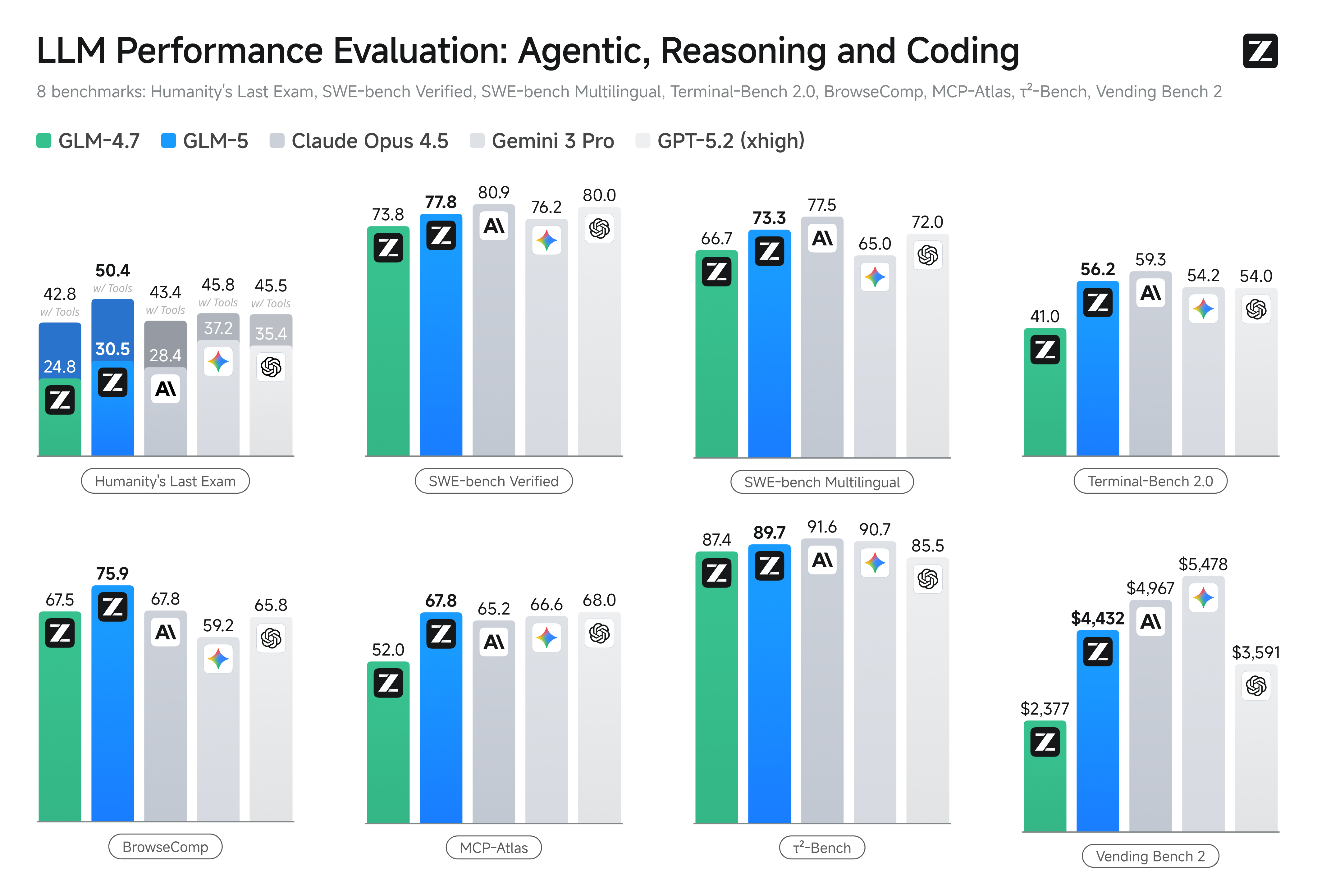
The GLM-5 model competes directly with GPT-5.2, Claude Opus 4.5, and Gemini 3.0 Pro on key benchmarks. On SWE-bench Verified, the GLM-5 model scores 77.8, falling between Gemini 3.0 Pro at 76.2 and Claude Opus 4.5 at 80.9. For agentic tasks, the GLM-5 model leads all open-source models on Vending Bench 2 and BrowseComp.
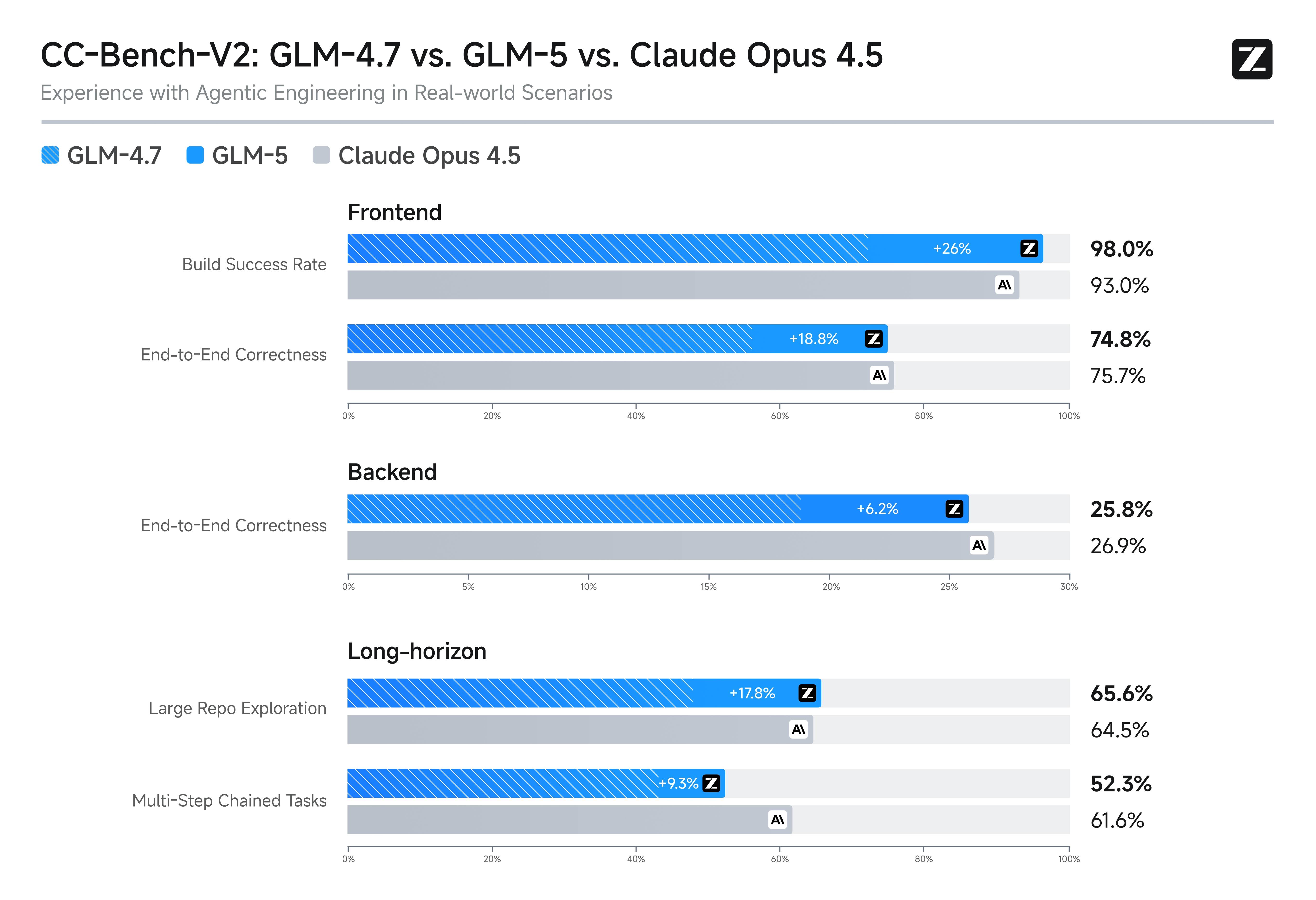
The GLM-5 model's primary competitive advantage is its combination of near-frontier performance with significantly lower pricing and open-weight availability. Teams that need frontier-level capability but want to avoid proprietary vendor lock-in should evaluate the GLM-5 model as a viable alternative.
Recommendation
Teams evaluating the GLM-5 model should run controlled benchmarks against their specific workloads using flagship GLM-5, and compare with GLM-5-Code when coding quality is the primary KPI. Focus on coding repair quality, tool orchestration reliability, and long-horizon task completion rather than aggregate benchmark scores alone. The GLM-5 model's real value depends on how well it performs on your particular use cases.