
GLM-5 benchmark results paint a detailed picture of where this model excels and where it still trails the competition. Rather than focusing on a single aggregate score, this breakdown covers each major GLM-5 benchmark category separately to help teams make informed evaluation decisions. All GLM-5 benchmark data referenced here comes from the published charts on docs.z.ai and the z.ai release blog.
GLM-5 Benchmark Overview
The GLM-5 benchmark suite covers eight major evaluation categories spanning coding, reasoning, agentic tasks, and long-horizon workflows. Zhipu AI positions GLM-5 as achieving state-of-the-art performance among open-source models while closing the gap with proprietary frontier models on most GLM-5 benchmark tasks.
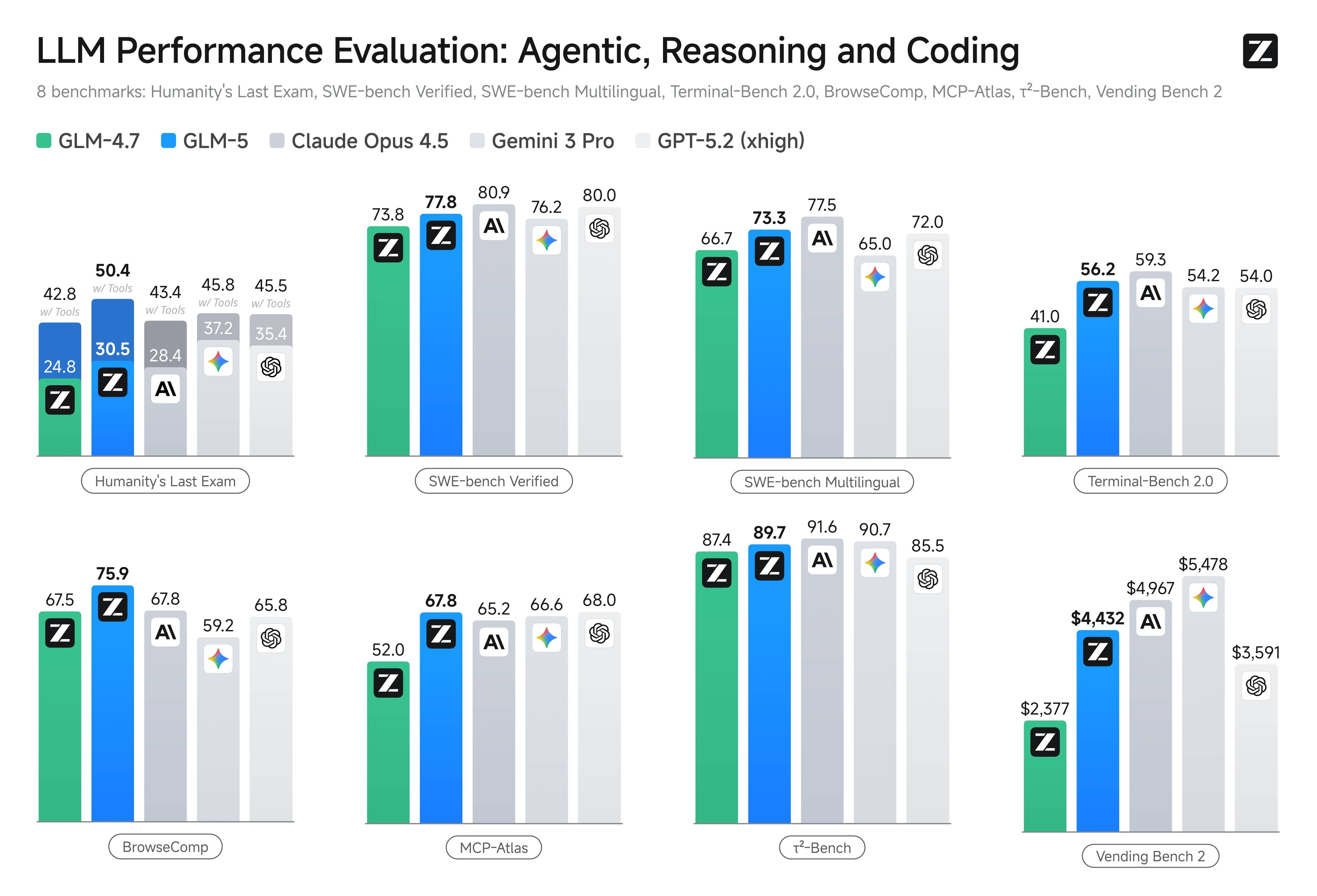
The GLM-5 benchmark results demonstrate significant improvement over the previous generation GLM-4.7 across all categories, with the largest gains appearing in agentic and long-horizon task evaluations.
SWE-bench: GLM-5 Coding Benchmark
SWE-bench Verified is one of the most closely watched GLM-5 benchmark metrics for engineering teams. This GLM-5 benchmark measures the ability to resolve real GitHub issues by generating correct code patches. GLM-5 scores 77.8 on SWE-bench Verified, placing it above Gemini 3.0 Pro at 76.2 and below Claude Opus 4.5 at 80.9.
For multilingual software engineering, the GLM-5 benchmark on SWE-bench Multilingual shows a score of 73.3. This GLM-5 benchmark indicates solid cross-language capability, important for teams working in polyglot codebases with Python, JavaScript, TypeScript, Java, and other languages.
The SWE-bench GLM-5 benchmark is particularly relevant because it tests real-world code repair tasks rather than synthetic coding exercises. A GLM-5 benchmark score of 77.8 on SWE-bench Verified suggests that GLM-5 can reliably fix real bugs in production codebases, though teams should validate this on their specific repositories and coding patterns.
Terminal-Bench: GLM-5 Agent Benchmark
Terminal-Bench 2.0 evaluates model capability in command-line task completion, a critical GLM-5 benchmark for teams building terminal-based agent workflows. GLM-5 achieves 56.2 on this benchmark, demonstrating competence in understanding command-line tools, composing multi-step terminal operations, and handling error recovery in shell environments.
This GLM-5 benchmark is particularly important for DevOps and infrastructure automation use cases where models need to navigate complex command-line environments, parse tool outputs, and chain operations together to achieve system administration goals.
Vending Bench 2: GLM-5 Business Simulation Benchmark
Vending Bench 2 is an agentic GLM-5 benchmark that simulates running a business, requiring the model to make strategic decisions, manage resources, and optimize for profit over multiple interaction rounds. GLM-5 achieves a final balance of $4,432, ranking first among all open-source models on this benchmark.
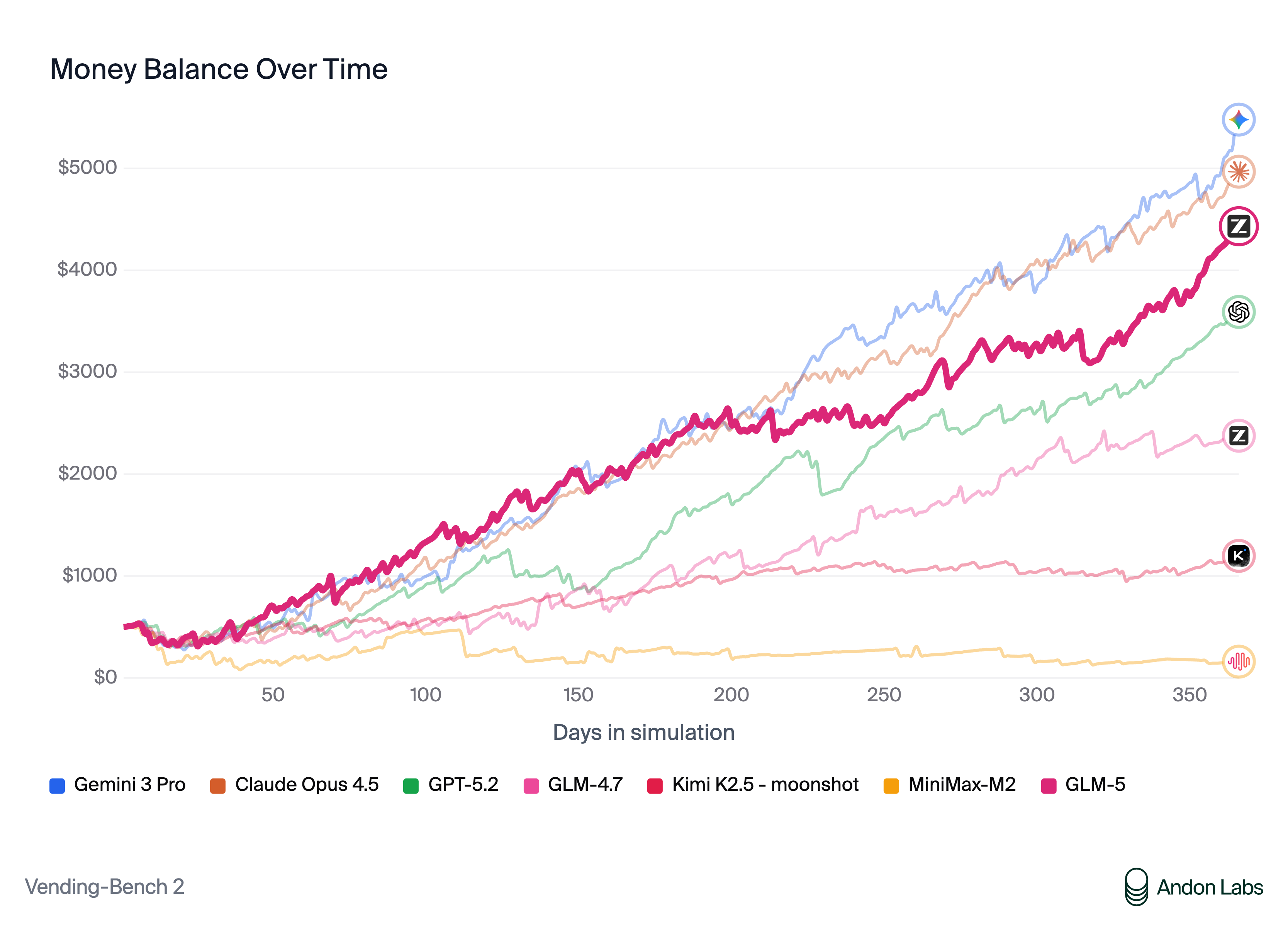
This GLM-5 benchmark tests long-horizon planning and decision-making capability that goes beyond single-turn code generation. The strong Vending Bench 2 performance suggests that GLM-5 is well-suited for agentic workflows that require sustained reasoning over many steps, such as automated project management, resource allocation, and strategic planning tasks.
MCP-Atlas: GLM-5 Tool Orchestration Benchmark
MCP-Atlas evaluates multi-step tool use and orchestration capability with a GLM-5 benchmark score of 67.8. This benchmark tests the model's ability to decompose complex tasks into tool calls, handle tool results, and chain multiple tool invocations together to solve problems.
For teams building agentic systems that rely on Function Calling and parallel tool use, this GLM-5 benchmark provides the most direct signal of production readiness. A score of 67.8 indicates strong but not perfect tool orchestration, meaning production systems should include error handling and retry logic for tool-call reliability.
BrowseComp: GLM-5 Web Navigation Benchmark
BrowseComp tests the model's ability to navigate web content and extract information through multi-step browsing tasks. GLM-5 shows strong performance on BrowseComp among open-source models, reflecting its capability in understanding web page structure, following links, and synthesizing information from multiple sources.
This GLM-5 benchmark is relevant for teams building web scraping agents, research assistants, and automated data collection workflows that require navigating real web content.
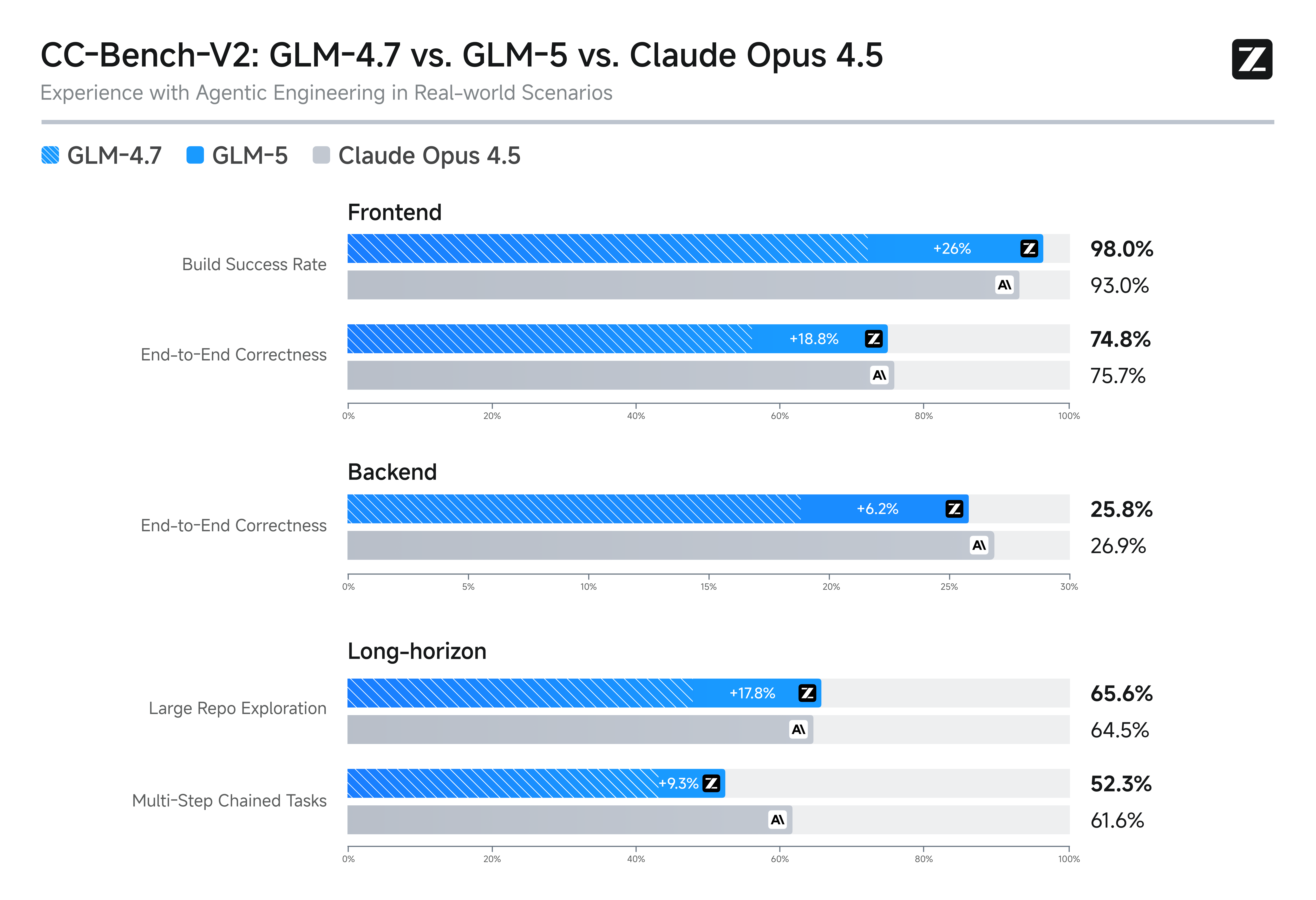
CC-Bench-V2: GLM-5 Engineering Benchmark
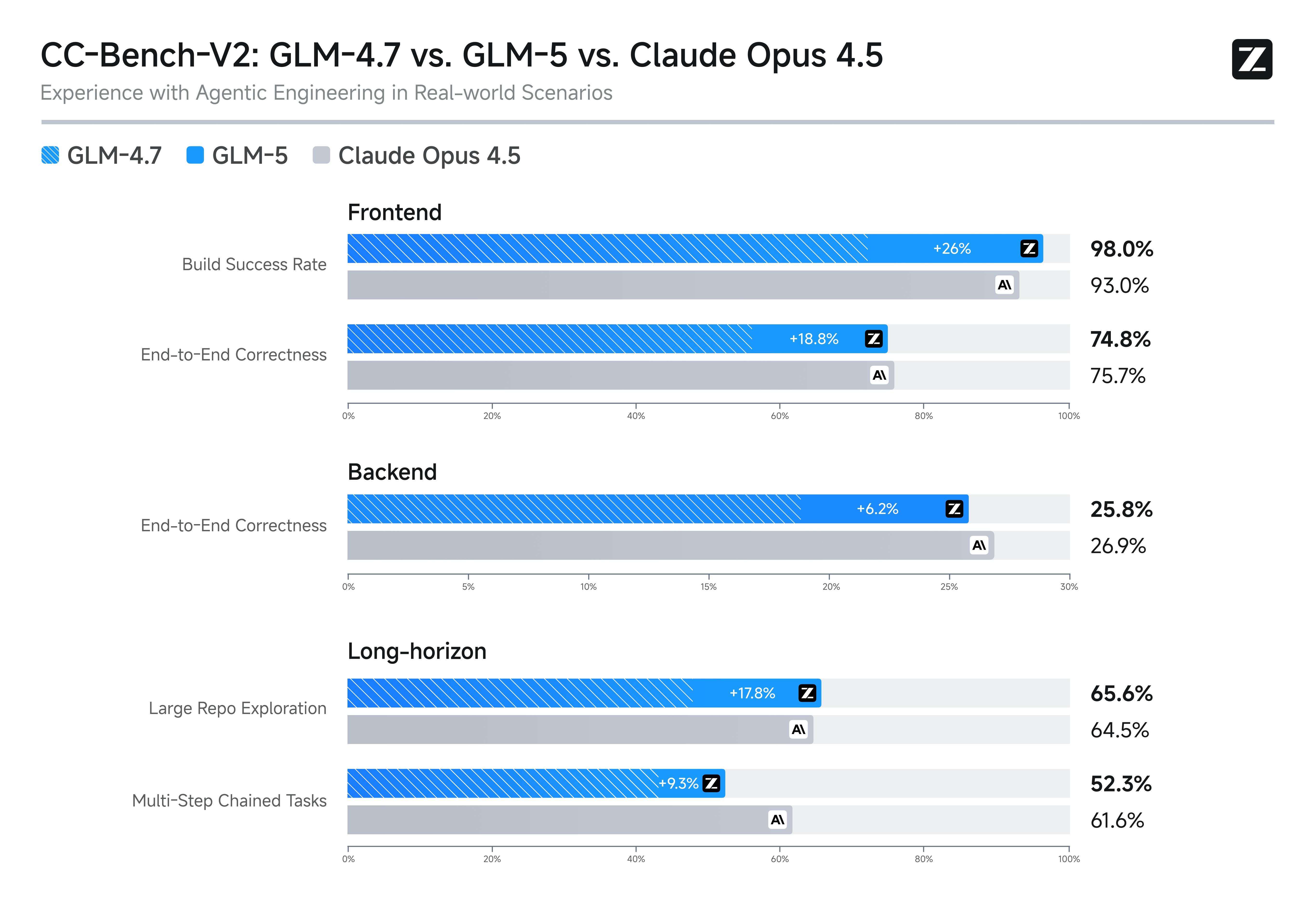
CC-Bench-V2 is a comprehensive GLM-5 benchmark covering real engineering scenarios across frontend, backend, and long-horizon tasks. This benchmark goes beyond isolated coding tasks to evaluate the model's ability to work on realistic engineering projects with multiple files, dependencies, and architectural considerations.
The CC-Bench-V2 GLM-5 benchmark results show competitive performance across all three categories, with particular strength in backend engineering tasks where GLM-5's systems engineering focus provides an advantage.
Hallucination Rate: GLM-5 Reliability Benchmark
One of the most notable GLM-5 benchmark results is the record-low hallucination rate on the Artificial Analysis Intelligence Index v4.0. With a score of -1 on the AA-Omniscience Index, GLM-5 achieves a 35-point improvement over its predecessor and leads the entire AI industry in knowledge reliability.
This GLM-5 benchmark is critical for production use cases where factual accuracy matters. A low hallucination rate means teams can place higher trust in GLM-5 outputs for documentation, research synthesis, and factual queries, though human verification remains important for high-stakes decisions.
From GLM-5 Benchmarks to Decisions
While GLM-5 benchmark scores provide useful directional signals, production teams should not rely on benchmarks alone. The recommended evaluation workflow is:
- Split your evaluation into coding repair, tool use, and long-horizon planning categories
- Build a representative test set with 20 to 50 real samples per category
- Run parallel tests against your current model and at least one alternative
- Track success rate, retry rate, latency, and cost per task
- Weight the results by the actual distribution of task types in your workload
This process is far more decision-grade than any single GLM-5 benchmark score and will give you confidence in whether GLM-5 is the right model for your specific production needs.