
Stage#1
Unified Base Model
GLM-5 uses a single unified model base, eliminating the need for separate models when switching between think and non-think usage.
GLM-5 MODEL HUB
Evaluate GLM-5 capability ceilings, compare benchmark scores, review API pricing, and explore the architecture — all in one place.
744B
40B
200K
MIT
Community
Watch these in-depth reviews and tutorials from the AI community showcasing GLM-5's capabilities.
Full test covering coding quality, multi-step task behavior, and direct model comparisons on agentic coding benchmarks.
AICodeKing
44.2K views · Feb 11, 2026
Hands-on demo with browser automation, game generation, and Python 3D tasks to evaluate real-world coding output quality.
Bijan Bowen
15K views · Feb 11, 2026
Use-case walkthrough from quick coding prompts to agentic engineering pipelines, exploring GLM-5 real-world deployment paths.
Fahd Mirza
3.5K views · Feb 11, 2026
GLM-5 is Zhipu AI's fifth-generation large language model, targeting complex systems engineering and long-horizon agentic tasks. It scales up from GLM-4.5 with 355B/32B active parameters to 744B/40B active, and grows pretraining data from 23T to 28.5T tokens.
Think and non-think modes share one base model, with differences mainly in post-training strategy.
DeepSeek Sparse Attention reduces inference cost while preserving 200K context capability for long-document workflows.
GLM-5 weights are available on Hugging Face and ModelScope under MIT license, with API access through multiple providers.
GLM-5 uses a unified model architecture with hybrid reasoning mode switching. Think and non-think share the same base, with DSA for long-context efficiency and the slime asynchronous RL infrastructure for training.
744B
Total Parameters
40B
Active Parameters
28.5T Tokens
Pretraining Data
Unified Think/Non-think
Reasoning Mode
GLM-5 uses a single unified model base, eliminating the need for separate models when switching between think and non-think usage.
Differences between think and non-think behavior are introduced in post-training, enabling quality and latency tradeoffs.
Hybrid reasoning can be enabled based on task complexity and workflow needs for flexible deployment.
DeepSeek Sparse Attention reduces inference cost while preserving long-context capability across large input sequences.
The slime framework provides asynchronous reinforcement learning for higher training throughput and faster iteration cycles.
GLM-5 supports Function Calling and parallel tool calls, enabling complex agentic workflows with multi-step orchestration.
Context window and output limits for GLM-5 across major providers. Displayed limits can vary by platform and routing layer.
200K context / up to 128K output
GLM-5 (docs.z.ai)
202,752 context
GLM-5 (OpenRouter)
up to 202,752
OpenRouter max completion
Limits vary by endpoint
Provider caveat
A 200K context window supports long-document QA, cross-file code analysis, and multi-step planning workflows.
GLM-5 supports up to 128K output tokens in official docs. Effective output limits can vary by provider and endpoint settings.
The 202,752 context number comes from OpenRouter. For production, verify effective limits on your target provider.
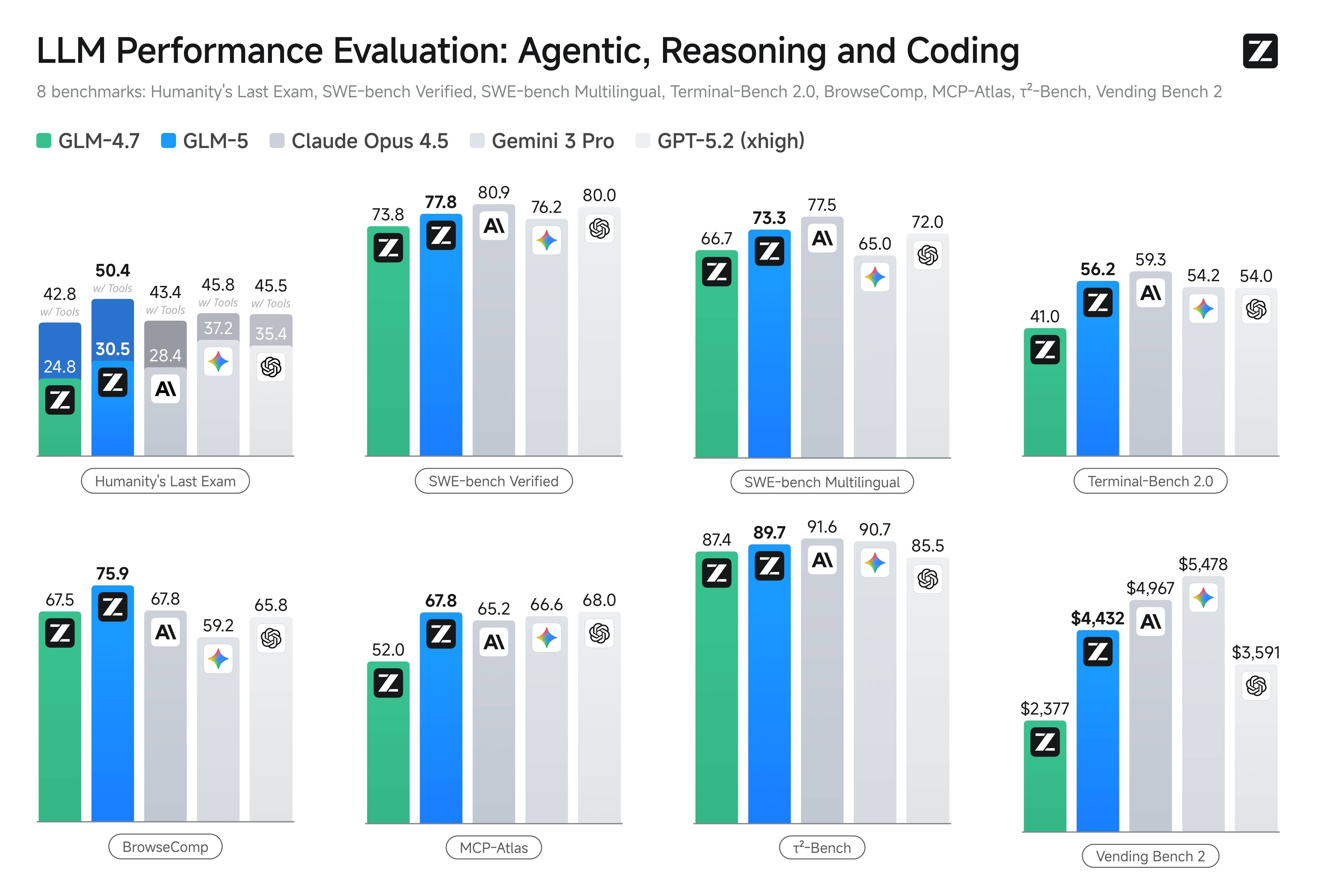
Published benchmark visuals covering agentic, reasoning, coding, and long-horizon tasks for side-by-side model comparison.
Sources: docs.z.ai and z.ai/blog/glm-5, captured February 12, 2026
Eight public benchmarks including Humanity's Last Exam, SWE-bench, Terminal-Bench, MCP-Atlas, and Vending Bench 2.
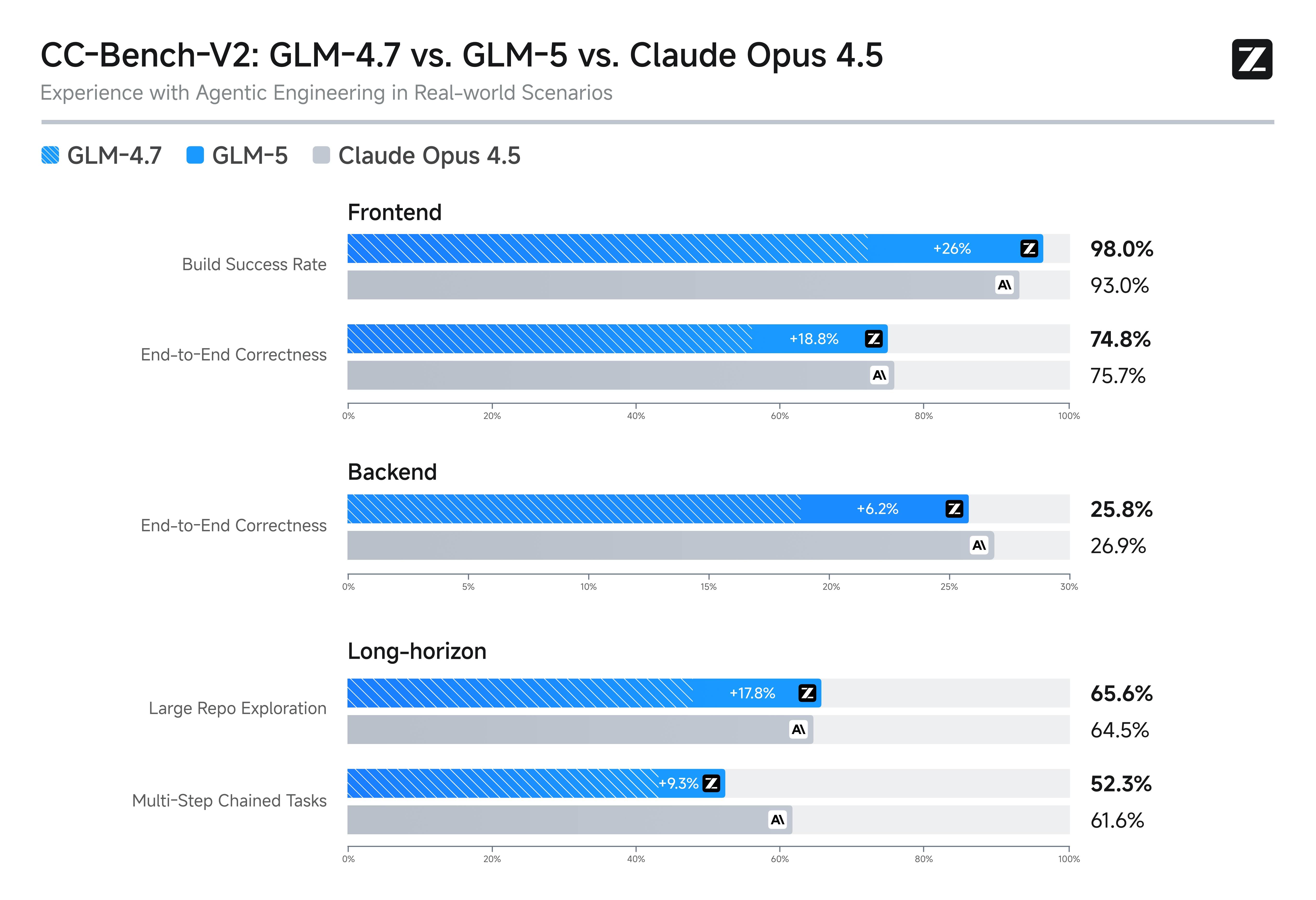
Comparison chart for frontend, backend, and long-horizon engineering tasks.
77.8
SWE-bench Verified
GLM-5 score on SWE-bench Verified for real-world code repair tasks.
73.3
SWE-bench Multilingual
Performance on multilingual software engineering tasks across multiple languages.
56.2
Terminal-Bench 2.0
Score on terminal-agent workloads measuring command-line task completion.
$4,432
Vending Bench 2
Final balance achieved by GLM-5 in the business simulation benchmark.
Pricing from docs.z.ai and OpenRouter as of February 12, 2026. All prices shown here are in USD; re-check provider pages before production launch.
$1.00 / 1M tokens
GLM-5 Input
$0.20 / 1M tokens
GLM-5 Cached Input
$3.20 / 1M tokens
GLM-5 Output
$1.20 in / $5.00 out
GLM-5-Code
Input $1.00 / 1M, cached input $0.20 / 1M, and output $3.20 / 1M in USD.
Input $1.20 / 1M, cached input $0.30 / 1M, and output $5.00 / 1M in USD.
Cached input storage is marked as limited-time free on the official pricing page.
GLM-5 is listed at $1 / 1M input and $3.20 / 1M output in USD.
Both docs.z.ai and OpenRouter list prices per 1M tokens; check provider billing granularity before launch.
Final billed cost may differ by routing policy, platform markup, and cache behavior across providers.
GLM-5 stands out for systems-engineering workloads, long-horizon agent tasks, competitive pricing, and record-low hallucination rates.
GLM-5 is positioned for complex systems engineering and high-complexity execution workflows with multi-step tool use.
Common questions about GLM-5 benchmarks, API pricing, context windows, and model capabilities.
As of February 12, 2026, docs.z.ai lists GLM-5 at $1.00/1M input, $0.20/1M cached input, and $3.20/1M output; GLM-5-Code is $1.20/1M input, $0.30/1M cached input, and $5.00/1M output. OpenRouter lists GLM-5 at $1/1M input and $3.20/1M output.
GLM-5 supports a 200K context window with up to 128K output tokens in official docs. OpenRouter currently lists 202,752 context, and effective limits can vary by provider endpoint.
Yes. GLM-5 has 744B total parameters with 40B active per token, using a sparse-activation MoE architecture with 256 experts and 8 activated per token.
GLM-5 scores 77.8 on SWE-bench Verified. In published comparison charts, Claude Opus 4.5 is 80.9 and Gemini 3.0 Pro is 76.2. GLM-5 ranks first among open-weight models on Vending Bench 2.
OpenRouter is a routing platform and may apply platform-level routing and margin policies. Always verify final billing rules and units on each provider page.
Yes. GLM-5 weights are available on Hugging Face and ModelScope under the MIT License, supporting local deployment with vLLM and SGLang.